【摘 要】 随着互联网的普及,网上药店也应运而生,在网上购买药品也成为一种大众化的需求。为了能够了解药品在电商平台中的销售情况,本文利用Scrapy爬虫框架高效地从网络上爬取药品数据,通过对爬取的药品数据进行可视化处理,为用户在网上买药提供参考。
【关键词】 网络爬虫;Scrapy框架;电商药品销量数据;数据可视化
1 引言
20世纪90年代初期以来, 随着国家医药改革的推进, 药品经营企业得到蓬勃发展。在零售药店快速发展中, 诞生了各种各样的新型药品零售业态。网上药店是一种伴随着互联网技术而产生的, 能使医药企业与个人消费者进行药品电子商务交易的虚拟销售场所。网上药店是医药电子商务的一个分支和重要组成部分, 能够实现在线提供药品基本服务和药品网上零售功能。为了了解药品在网上的售卖状况,本文以借助天猫网为例,设计一个基于 Python 中的 Scrapy 框架的药品数据爬取工具,从天猫网上垂直搜索相关数据并按结构化存储,然后利用 DataV 数据可视化平台和 Microsoft Office PowerPoint 两种方法进行可视化处理,使用户直观的了解电商药品销售的相关信息,从而得出相关结论。
2 网络基础
2.1 网页组成
网页可以分为三个部分:HTML、CSS、JavaScript。其中 HT⁃ ML是网页中最重要的部分,它通过标签的方式定义了各种各样的元素样式,比如文字,图片,视频等。CSS是网页排版的一种标准,它能够调整网页的 UI 样式,能够使网页变得更加的美观。 JavaScript定义了网页的动作,提供一些动画效果,会让使用者感到非常舒适。
2.2 HTTP基本原理
当我们每天在在浏览网页时,会发生什么呢?首先,PC或者手机浏览器会发送一个Request请求给网站的服务器,服务器会根据请求的内容来返回一个Respond给使用者,这就是一个简单的HTTP请求过程。比如,在百度的搜索栏中输入:爬虫,那么浏览器会生成一个链接:https://www.baidu.com/s?ie=utf8&wd=爬虫 &tn=78040160_26_pg&ch=8,从中可以看出 wd 字段表示的就是要搜索的内容。
3 网络爬虫
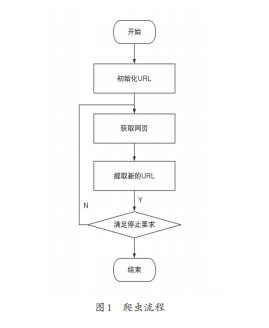
互联网就是一张大网,信息就像是在这张大网上的结点一样,而网络爬虫就可以在大网上移动,爬虫通过一个节点,就会获取一个信息,然后再爬取下一个节点,反反复复之后,就会得到大量的数据信息。网络爬虫的流程分为三步,首先是获取网页内容,然后从网页中提取数据,最后持久化保存数据。
爬虫的爬取原理十分简单,从最开始的第一个URL开始获取药品数据,爬取这个网页数据并且爬虫会收集此网页中没有被爬取过的药品数据链接,加入到未爬取药品数据链接队列,最后从未爬取药品数据链接队列中取出每一个药品数据链接,直到爬取到每一个药品数据为止,爬虫才会结束。具体流程如图1 所示。
4 Scrapy爬虫框架
Scrapy 是一套纯 Python 语言开发的,用于爬取网页内容或 各种图片并提取结构化数据的开源网络爬虫框架,可以应用于数据挖掘、信息处理或者存储数据等一系列的操作中,是目前 Python中使用最受欢迎和最广泛的爬虫框架。其框架主要由以下几部分组成,引擎(Scrapy Engine),处理系统数据流,整个框架的核心;调度器(Scheduler),维护请求队列;下载器(Download⁃ er),下载网页内容;爬虫(Spiders),定义网页的解析规则;项目管道(Pipeline),清洗存储数据。如下图2 所示。
5 基于Scrapy框架的电商药品数据爬虫设计
5.1 确定爬取对象
天猫网作为目前较大的综合性购物网站,拥有大量药品售卖数据。本文实现对天猫网上药品销售板块的数据爬取,主要对感冒药、跌打损伤药、消化不良药三类药品的药品名称、品牌、销量、剂型、类别等信息进行爬取,将药品数据过滤抽取最终存储在MySQL数据库中,以便于利用绘图软件进行绘制相应的数据分析图,能够对数据进行直观的分析。具体爬取思路流程图如图3所示。
5.2 设计功能框架
为了能够爬取数据,首先查看浏览器发送给天猫服务器的 Request 请求和服务器返回给浏览器的 Response响应,查看多个 Request 请求中 URL 的相同点,找出一定规律后,然后运用 Scra⁃ py 爬虫框架来编写多个Request请求 ,模仿浏览器的请求,最终获取数据。
基于 Scrapy 的药品信息爬取框架分为四大模块,分别是数据模块、爬取模块、配置模块以及数据处理模块。其功能架构图如图4所示。
其中,在数据模块items.py中定义要爬取的药品数据信息字段,包括药品名称、价格、销量、剂型、类别等信息,方便构造出药品实体对象,易于将爬取后的数据导入MySQL,可以使药品数据持久化存储。
爬取模块在四个模块中最为重要,tiaomao.py 是爬取模块中实现爬取数据的核心文件。爬取药品数据网页、获取药品信息、跳转页面等核心操作全部由此文件完成。从给定的初始URL开始爬起,在初始的URL中,首先利用Xpath在药品目录页中找到所有药品所在区域的
标签,然后遍历
下面所有药品目录信息,从中提取药品详情页的href属性,直到获取所有的每一个药品详情页链接,这就完成了对于一个药品目录页的查询。接下来根据药品目录页中下面的分页编号对所有药品目录页中的所有药品详情页href的进行爬取。对每一个上面爬去到的药品详情页href,利用Python封装Request请求,获取服务器发回来的Respond响应后,利用Xpath首先在药品详情页中找到药品信息的总属性标签,根据总属性标签查找它含有药品单个属性信息的详细标签,在详细标签中循环提取该列表中所有标签,如名称、规格、类别等所有的药品数据属性,并且根据属性所属类别存入数据模块items.py中构造的药品数据实体中,这就会产生一个药品实体,利用pymysql库将药品实体对象存入MySQL数据库,即完成数据获取的操作。
在数据处理模块pipelines.py中定义对爬虫爬取下来的数据进行降噪的处理方式,其中包括过滤、存储等操作。该文件从 tianmao.py 文件中获取爬取到的信息,对于含有非法字符的数据进行清洗和过滤,在实际操作过程中,遇到了一些乱码的文字,设置过滤条件即可过滤全部数据噪声。
在配置模块的 setting.py,它是项目的一个全局性配置文件,包含Scrapy项目的名称、下载延迟、Scrapy执行的最大并发请求数等信息。
5.3 存储爬取数据
为了方便用户简洁、直观地查看爬取数据,本文将爬取的数据利用pymysql库存入MySQL数据库。每条记录由药品属性字段组成,所有记录都有完全相同的字段序列,并且利用 Navicat Premium 12将数据库中的所有记录直接导入Microsoft Excel中,方便用户直观的查看数据。爬取结果的部分数据如表1所示。
5.4 数据可视化处理
感冒药作为药品零售市场的一大类,一向都是兵家必争之地,本文利用关键字“感冒药”在电商中搜索并爬取数据,并对爬取数据进行市场分析以及可视化处理,生成二维图表,从中获取相关信息。
例如,以数据中感冒药销量数据为例,做成条形图,从中可以清晰的看到,在 2019 年 2 月电商平台中,感冒灵颗粒销量最好,比第二名的药品还多出很多。销量第二名是枇杷露,第三名则是耳熟能详的板蓝根颗粒了。见图5。
相关知识推荐:职称论文要求是几年内发表的
DataV数据可视化这一平台是使用数据化可视化应用的方式来分析并展示繁杂数据的一个可视化工具,它旨在让更多的人看到数据魅力,它能够帮助非专业的数据可视化工程师通过图形化的界面轻松搭建专业水准的可视化应用。将爬取后的结 果导入到 DataV 平台后,调整显示的图形样式,字体,布局等参数,会将数据生成动态的可视化图表,以感冒药剂型为例,生成的动态饼图如图6所示。从图中可以清晰的看到在感冒药各种剂型的占比情况,其中颗粒剂型在感冒药的剂型占比重高达 52%,其次是口服液类型的感冒药也受到大众的青睐。
6 结语
本文在网上药店逐渐发展的背景下,研究了一种基于Scrapy 框架下的爬虫工具,实现了对天猫网站平台下药品信息的自动爬取。测试结果发现,在延迟设置为1秒的情况下,平均每分钟可以自动爬取240-280条数据,并且将爬取的信息绘制成数据分析图,为用户购买药品提供参考价值。——论文作者:闫 志 国 , 宛 楠 , 严 迪 , 许 超 , 秦 逸 飞 , 齐 前
参考文献
[1]曾建雄.我国网上药店的发展现状与对策探讨[J].经济研究导刊,2019 (8):22-23.
[2]陈燕.基于Scrapy爬虫框架的安居客租房数据爬取[J].轻工科技,2019, 35(9):74-75.
[3]樊宇豪. 基于Scrapy的分布式网络爬虫系统设计与实现[D].电子科技大学,2018.
[4]安子建.基于Scrapy框架的网络爬虫实现与数据抓取分析[D].吉林大学,2017.
[5]舒德华.基于Scrapy爬取电商平台数据及自动问答系统的构建[D].华中师范大学,2016.
转载请注明来自:http://www.lunwencheng.com/lunwen/dzi/21828.html
